Table of Contents
Fraud Detection
In Simple word, Fraud Detection is the technique used to detect frauds in any system or process.
- Fraud can be defined as a criminal activity, involving false representations to gain an unjust advantage (Concise Oxford Dictionary)
- The Association of Certified Fraud Examiners estimates that U.S. organizations lose about 7% of their revenues to fraud. If this were to hold true for all organizations contributing to the Gross Domestic Product of about $14 trillion for 2007, fraud losses could be as high as $1 trillion.
Issues with Fraud Detection
- Fraud is usually a rare event. Identifying fraud is difficult because of its rarity and because its very nature is stealthy.
- We need accurate models to make effective detection.
- The vast majority of the records (i.e., 99.9%) may be legitimate. Only 0.1% of the records may be fraudulent. Here a 99% accurate model will lead to too many false alarms.
- Say we have million transactions. As per above, 1000 are fraudulent. With 99% accuracy, i.e. 1% inaccuracy (false positives, false negatives), total alarms will be 1% of 0.999 million false alarms and 990 (99% of 1000) true alarms.
Total alarms = 9990 + 990 = 10980, out of which more than 90% are false alarms.
- Often, the extra accuracy is associated with higher cost, but the cost of not doing so may be much higher.
Fraud is Evolving
- Fraudsters may adapt quickly to many fraud detection methods, by devising novel and increasingly subtle ways to get away with it. Also, fraud detection schemes must evolve also to try to keep up with (and get ahead of) fraudsters.
Large Data Set Processing Needed
- Large credit card issuers like Capital One may process billions of transactions per year. Even a very small percentage of fraud among these billions of transactions can result in proportionately large losses.
- Telecom companies handle billions of calls in a month.
The Fact of Fraud is Not Always Known during Modeling
- We need to use both supervised and unsupervised methods to detect fraud.
Fraud is Very Complex
- The complexity is partly due to the fraudster’s need for stealth and secrecy, and partly due to the intentional obfuscation of the trail of evidence indicating fraud.
Fraud Detection May Require the Formulation of Rules Based on General Principles, “Red Flags,” Alerts, and Profiles
- General principle: The incidence of fraud is more likely when the opportunity is high and the potential gains are large.
- A “red flag”: A large number of accidents or claims is made by one individual.
- An alert: A new product is introduced before fraud management systems are put in place.
Fraud Detection Requires Both Internal and External Business Data
- Internal data describing their business events (selling things or providing services).
- External data such as demographic data, firmographic data (profile of businesses), psychographic data (people with various attitudinal and philosophical views).
Very Few Data Sets and Modeling Details are Available
- Fraud data sets and modeling methodologies are tightly kept secrets. Companies do not share with anyone.
Types of fraud models
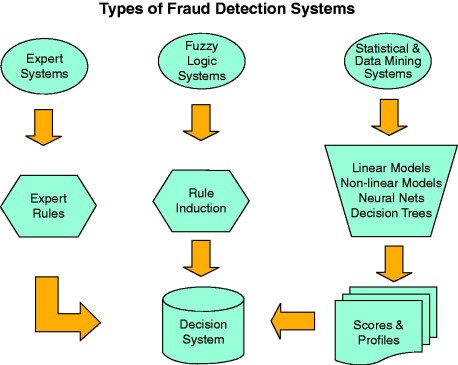
- Early fraud models employed expert systems to detect fraudulent events. An expert system is a collection of expert opinions on a number of decision criteria. These systems induced rules from the responses of a group of experts in the field. These rules can be coordinated into a flow chart leading to a decision.
- The problem with expert systems is that they are based on subjective inputs that may be contradictory
- Subsequent fraud detection systems used automated rule induction engines, based decision tree technology, and fuzzy logic. Some of these fraud detection systems are still marketed today (iPrevent by Brighterion).
- The Fair Isaac fraud detection systems Falcon Fraud Manager, eFalcon, and LiquidCredit Fraud Solution are built around a sophisticated system of predictive variables derived from extensive historical customer data. These predictors have been selected by many years of modeling fraud in many companies. The variables are submitted to a powerful backpropagation neural net.
Supervised Methods for Fraud Detection
Several elements are crucial to the successful supervised fraud model
- The fraud event and the relationship of that event to specific transactions or responses of the fraudster must be accurately identified
- Historical data of past transactions or responses must be available to derive powerfully predictive variables
- Profiles of the past behavior and actions of both the fraudsters and the nonfraudsters must be built and employed in the modeling methodology
Fraud can occur in many aspects of business, for e.g.:
- Credit card fraud: Stealing or counterfeiting credit card numbers, or nonpayment of accounts
- Application fraud: Untrue statements on a credit application, leading to assignment of an artificially low credit risk
- Claim fraud: Submitting inflated or false claims
- Life insurance: False or “engineered” death claims
- Health care fraud: False billings by health care providers etc.
Predictive variables need to be identified for each type of fraud.
Detection of money laundering and other financial crimes
To detect money laundering and other financial crimes, it is necessary to integrate information from multiple databases such as bank transaction databases, and federal or state crime history
Multiple data analysis tools can then be used :
- Data visualization tools to display transaction activities using graphs by time and by groups of customers
- Linkage analysis tools to identify links among different customers and activities
- Classification tools to filter unrelated attributes and rank the related ones
- Clustering tools to group different cases
- Outlier analysis tools to detect unusual amounts of fund transfers or other activities, and
- Sequential pattern analysis tools to characterize unusual access sequences



